Dans le cadre de ce module nous allons nous concentrer sur le recueil des données du point de vue d’un annonceur, propriétaire d’un site web.
Voici les différents thèmes que nous allons aborder :
- Quelles données collecter ?
- Comment les données sont-elles collectées ?
- Contraintes réglementaires
- Contraintes techniques
- Les éléments pouvant affecter la collecte
- Stockage de la donnée
- Et pour vous aider : terminologie et professions associées
Quelles données collecter ?
La qualité doit nécessairement primer sur la quantité. En premier lieu, il convient de prendre en compte le business modèle du site / de l’application dont on cherche à mesurer les performances; et le comportement attendu : pure player 100% online; ROPO, click & collect, etc….
Voici un parcours ‘pure player’ :
Dans ce cas, l’aquisition et la conversion se font en ligne; il n’y a pas de rupture.
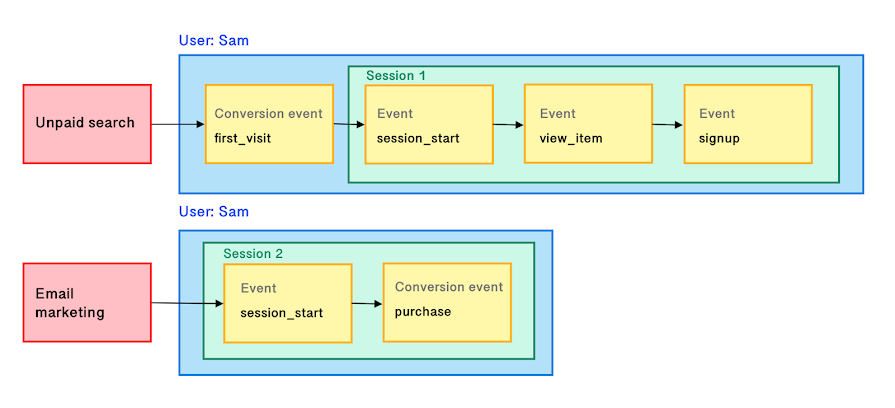
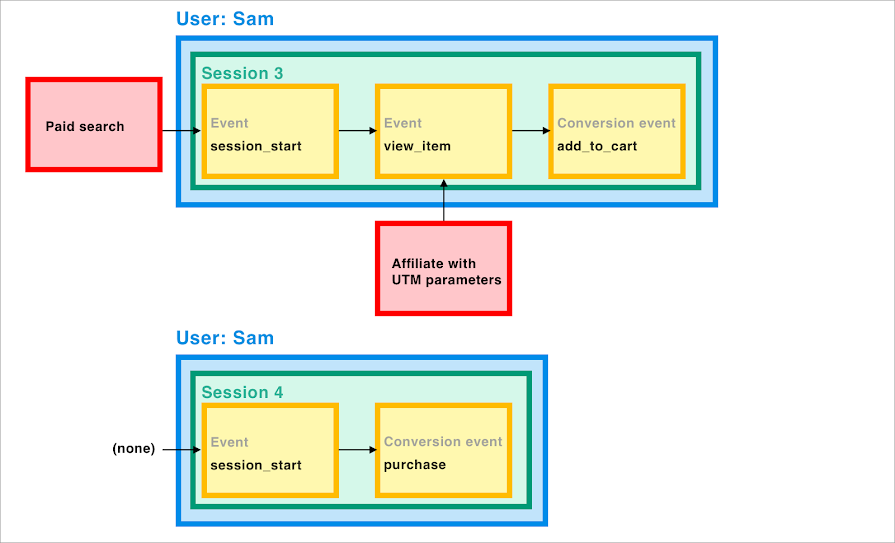
Voici un parcours ROPO
L’acronyme ‘ROPO’ signifie ‘Research Online, Purchase Offline’. L’objectif reste de faire venir en boutique, même si l’importance du e-commerce va grandissant. C’est le cas du secteur du luxe, typiquement. Voici ci-dessous les parcours de deux acteurs poursuivant le même objectif : faire venir en boutique.
Dans ce cas, l’analyse des données permettra d’observer une corrélation entre les investissements online et les ventes online. Des modèles économétriques pourront être construits, nourris par ces différentes sources de données. On parle de Marketing Mix Modeling.
On distingue deux phases clés pour lesquelles nous aurons besoin de mesures :
- Phase d’acquisition : Optimiser ses investissements publicitaires : cibler la bonne audience, avec un bon format d’annonces, sur le bon placement, etc… On note l’importance du respect de la convention de nommage par les agences qui mettent en oeuvre les campagnes : nom des campagnes et urls de redirection permettront d’affecter les mesures (impression, clics, etc…) à la bonne annonce
- Phase de conversion : Observer les comportements de navigation, les usages, pour comprendre comment les améliorer et in fine augmenter son taux de conversion : UX, algorithmes, etc… On note d’importance ici de deux documents :
- la convention de nommage définissant les urls de redirection, qui permet de retrouver facilement la source de trafic ayant permis de générer la conversion.
Bien entendu, si la conversion se fait offline (en boutique par exemple), on va importer les données du système d’encaissement, les données permettant de mesurer la fréquentation des magasins, etc…
Exercice pratique : plan de taggage
Cet exercice est à réaliser en groupe de 3/4 personnes.
Choisissez un site web, et définissez, en fonction de son business model les données clés que vous souhaiteriez recueillir (macros et micros conversions). Puis, construisez une ébauche de plan de taggage.
Pour nourrir votre inspiration, voici un autre exemple de plan de taggage, basé sur ce site (formation.dibenn.com).
Format attendu : présentation sous forme de slides. Temps laissé pour réaliser l’exercice : 40 minutes.
Exercice pratique : observation des urls de redirection pointant sur un site
Cet exercice est à réaliser en groupe de 3/4 personnes.
Retrouvez ici l’énoncé de l’exercice
Format attendu : présentation sous forme de slides. Temps laissé pour réaliser l’exercice : 40 minutes.
Comment les données sont-elles collectées ?
Phase d’acquisition :
Il s’agit des visiteurs que l’on va chercher par définition en dehors de l’éco-système du site web / de l’application sur lesquels on souhaite les faire arriver. Chaque plateforme dispose sur son ou ses domaines de moyens de détecter les impressions et différentes interactions (‘like’, ‘share’, ‘retweet’, ‘comment’, etc…)
Importance de l’IA- Pour la constitution d’audience : anticipation du comportement des cibles
- Dans les algorithmes des outils d’enchères
- Pour estimer le comportement des internautes ayant refusé les cookies
A titre d’exemple, voici les données qui peuvent être recueillies par la régie publicitaire de Google.
A retenir : la grande majorité des annonces fonctionne avec un système d’enchères, qui fonctionne exactement comme une place de marché boursière. De multiples facteurs sont pris en compte dans les algorithmes des plateformes et moteurs de recherche pour déterminer quelle annonce afficher (appartenance à la cible, montant de l’enchère, jour/heure, type de device, historique de navigation, qualité de l’annonceur : ‘quality score’, etc…).
Phase de conversion :
Sur un site web ou une application, on va utiliser des scripts / pixels / tags pour collecter la donnée. C’est le navigateur qui va se charger de cette collecte.
Vous retrouverez sur cette page un exposé des principes du tracking.
NB : importance de l’IA pour la proposition de contenus adaptés (netflix, facebook, etc…). Pour aller plus loin : voir le film : social dilemma
Les contraintes réglementaires
La Cnil se montre particulièrement vigilante concernant les données personnelles que les platformes, applications et sites peuvent collecter.
‘L’exemption’ permet, sous certaines conditions, de collecter des données de navigation, même si l’utilisateur n’a pas donné son consentement (consentement de niveau 1). Tous les outils ne peuvent pas en bénéficier.
Un des outils les plus répandu du marché, Google Analytics, ne peut être utilisé valablement du point de vue de la Cnil que si l’on a au préalable mis en place une ‘pseudonymisation’ de l’identifiant utilisateur, permise grâce à l’utilisation d’un proxy.
Retrouvez ici plus d’informations sur le sujet.
NB : importance de l’IA : un algorithme permet l’estimation du comportement des individus n’ayant pas accepté les cookies (Google Consent). Voir les détails ici
Exercice pratique : observation des hits
En consultant la console de votre navigateur, vous pouvez observer les données transférées depuis votre site vers les différentes plateformes et outils site-centrics.
Deux solutions s’offrent à vous :
- Utiliser le menu ‘network’ de la console
- Ne marche pas nécessairement pour tous les sites, et tous les outils de tracking : utiliser une extension (sur chrome), pour observer les hits de collecte de façon plus aisée. Voici une vidéo qui illustre comment faire.
Ce qui est demandé :
- Vérifier la conformité de certains sites avec les exigences de la cnil : assurez-vous qu’aucun hit n’est déclenché tant que le consentement utilisateur n’a pas été donné (CMP).
- Observez toutes les données qui peuvent être collectées. A titre d’exemple, voici ce que collectait il y a quelques années une célèbre marque de vêtements. Auriez-vous envie de compléter le plan de taggage réalisé en début de journée avec des dimensions personnalisées (i.e d’autres éléments propres à votre site, votre audience )?
Format attendu : présentation sous forme de slides. Temps laissé pour réaliser l’exercice : 40 minutes.
Les contraintes techniques
Retrouvez ici plus d’informations sur le sujet
Les éléments pouvant affecter la data quality
La data quality qualifie l’état de complétion de la donnée recueillie, ainsi que sa correspondance avec le schéma attendu, et la cohérence d’ensemble (ex : on ne peut pas, pour une annonce, avoir plus de clics que d’impressions).
Stockage de la donnée
Données structurées et non structurées
Les données structurées sont très précises et stockées dans un format prédéfini, alors que les données non structurées sont une conglomération de nombreuses données de différents types qui sont stockées dans leurs formats en mode natif. Source: https://www.talend.com/
Dans les faits, pour les besoins du pilotage des activités marketing (i.e calcul du ROI par visuel, par type de produit promu, etc..), les données sont structurées.
Donnée ‘brute’, avant traitement
Au lieu de devoir établir des connecteurs avec chaque plate-forme, on peut faire appel à des agrégateurs de flux, qui peuvent aussi proposer de stocker la donnée collectée.
Voir un exemple : funnel.io
Stockage de la donnée traitée
Le traitement de la donnée brute nécessite à minima disposer d’outils de gestion de bases de données, d’héberger la donnée retraitée et de la renvoyer vers un outil de data visualisation.
C’est typiquement ce que proposent -entre autre- Google Cloud Platform, Microsoft Azure, AWS, etc… L’avantage est que l’aspect ‘maintenance’ des infrastructures est totalement géré; l’utilisateur n’ayant pas à se soucier de ces aspect.
Voir un exemple : Google Cloud Platform
Terminologie
- Pixel / script / tag :
- TMS : Tag Management System
- Datalake:
- Datamart
- DMP : Data Management Platform (‘ancêtre’ de la CDP)
- CDP : Customer Data Platform
- CMP: Consent Management Platform
- Data mining (+ sur la partie analyse)
- Data Quality
Professions associées
- Architecte réseau
- DPO : Data Privacy Officer ou Data Protection Officer
- CDO: Chief Data Officer
- Tracking specialist
- Data Analyst
- Data Scientist
Retour à la page ‘table des matières’ pour cette formation
_____

